
사부작사부작해요
백준 9935 문자열 폭발 - KMP가 안되는 이유 본문
주어진 문자열에서, 패턴(=폭발 문자열)과 일치하는 부분 문자열을 모두 삭제하는 문제이다.
문자열에 일치하는 패턴이 없을 때 까지 계속 반복한다.
KMP로 풀어서 제출하면 시간초과로 통과하지 못한다. 패턴에 반복/공통되는 문자열이 없기 때문이다.
다른분들 풀이를 확인했는데, 스택을 많이 사용하더라.
폭발 후 문자열을 연속해서 폭발시킬 수 있어 논리가 단순해 스택을 많이 사용하는 것 같다.
왜 KMP가 안되는지, 왜 스택을 사용했는지, 특히 str 타입이 아니라 list 타입을 써서 해결한 이유는 뭔지 알아보자.
KMP로 풀었을 때
문제를 다시 읽다보니, 조건에서 KMP로 풀지 말라고 알려주고 있었다.
폭발 문자열은 같은 문자를 두 개 이상 포함하지 않는다.
KMP는 패턴에 공통 문자열이 많을수록 효과적인 알고리즘이다. 패턴 안에 반복되는 문자들이 있어야 검사하지 않고 넘어갈 수 있는 경우가 생기니까.
그런데 이 문제에서는 패턴에 동일한 문자조차 없다. 패턴 안에 공통되는 문자열이 전혀 없다는 뜻이다. 따라서 KMP 테이블의 원소, 즉 최대 공통 문자열의 길이는 언제나 0이다.
이 경우 KMP로 풀면 시간복잡도는 O(문자열의 길이*패턴의 길이)이다. 모든 문자열을 순서대로 확인하는 것과 차이가 없다.
아래는 KMP 알고리즘으로 풀이한 코드이다.
def solution(string, bomb):
bomb_pattern_table = make_KMP_table(bomb)
bomb_positions = kmp(string, bomb, bomb_pattern_table)
while bomb_positions:
string = explode(string, bomb_positions, len(bomb))
bomb_positions = kmp(string, bomb, bomb_pattern_table)
if string:
return string
return "FRULA"
def explode(string, bomb_positions, bomb_size):
# string에서 bomb_positions에 있는 폭발문자열들을 제거하여 return
last_bomb_position = bomb_positions[0]
new_string = string[:last_bomb_position]
for i in range(1, len(bomb_positions)):
bomb_position = bomb_positions[i]
new_string += string[last_bomb_position+bomb_size:bomb_position]
last_bomb_position = bomb_position
new_string += string[last_bomb_position+bomb_size:]
return new_string
def make_KMP_table(pattern):
pattern_size = len(pattern)
table = [0] * pattern_size
affix_length = 0
for i in range(1, pattern_size):
while affix_length > 0 and pattern[i] != pattern[affix_length]:
affix_length = table[affix_length - 1]
if pattern[i] == pattern[affix_length]:
affix_length += 1
table[i] = affix_length
return table
def kmp(sentence, pattern, pattern_table):
ret = []
sentence_size = len(sentence)
pattern_size = len(pattern)
affix_length = 0
for i in range(0, sentence_size):
while affix_length > 0 and sentence[i] != pattern[affix_length]:
affix_length = pattern_table[affix_length-1]
if sentence[i] == pattern[affix_length]:
if affix_length == pattern_size - 1:
ret.append(i - pattern_size + 1)
affix_length = pattern_table[affix_length]
else:
affix_length += 1
return ret
# 데이터 입력
sentence = input()
bomb = input()
print(solution(sentence, bomb))스택을 쓰자
전체 문자열을 확인해봐야 한다. 그러나 패턴의 모든 문자열과 매번 비교를 할 필요는 없다.
확인하고 있는 문자열과 패턴의 마지막 문자열이 일치하는지 우선 확인한다.
일치한다면 해당 부분과 패턴 전체를 비교하고 일치하지 않는다면 다음 문자열을 확인한다.
마지막 문자열과 비교하는 이유는 구하고자하는 결과 문자열을 스택을 통해 만들 것이기 때문이다.
스택을 사용하는 이유는 다른 자료구조를 사용할 때 보다 반복문 작성이 쉬워서이다. 논리가 단순해서 금방 구현할 수 있다.
def explode(string, bomb):
bomb_size = len(bomb)
if len(string) < bomb_size:
return string
stack = []
for i in range(len(string)):
stack.append(string[i])
if stack[-1] == bomb[-1]:
if "".join(stack[-bomb_size:]) == bomb:
del stack[-bomb_size:]
if stack:
return "".join(stack)
return "FRULA"
# 데이터 입력
sentence = input()
bomb = input()
print(explode(sentence, bomb))문자열을 리스트로 관리
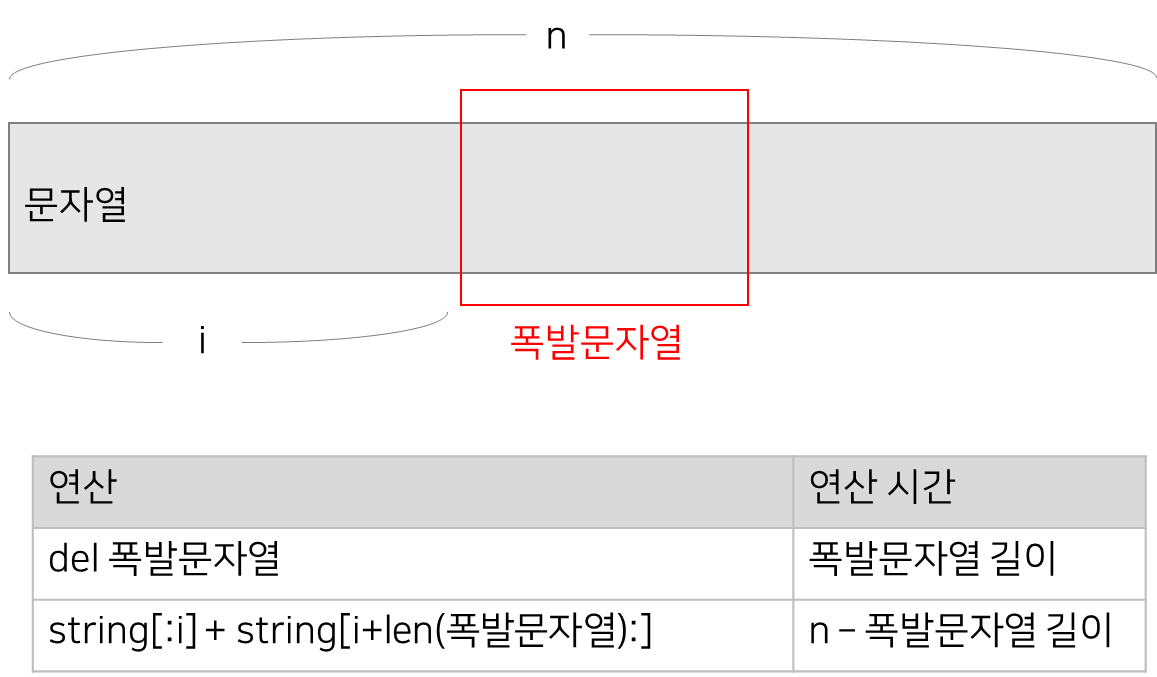
난 처음에 위의 KMP 코드 17번 라인처럼 문자열을 슬라이싱하고 연결해서 썼다.
그것보다 스택 코드의 10번 라인처럼 문자열을 리스트로 관리해서 del 연산을 쓰는 것이 더 좋다.
길이가 N, M인 문자열을 파이썬 연산자 +를 사용할 경우 시간복잡도는 O(N+M)이다.
리스트에서 N개의 원소를 del 연산자로 삭제하는 경우 시간복잡도는 O(N)이다.
이 경우, 문자열을 반복적으로 이어주는 것 보다, 리스트로 관리해서 del 하는 것이 더 효율적이다.
대개의 경우 폭발 문자열이 문자열 길이의 절반보다 작을 것이기 때문이다.
* 문자열의 최대 길이는 1,000,000이고 폭발 문자열의 최대 길이는 36이다.
REFERENCES
스택 풀이: https://co-no.tistory.com/25
파이썬 string concat 시간복잡도: https://stackoverflow.com/questions/37133547/time-complexity-of-string-concatenation-in-python
'알고리즘 > 문제풀이' 카테고리의 다른 글
| 쉘스크립트로 알고리즘 문제 풀이 파일 관리 자동화 (0) | 2022.09.12 |
|---|---|
| 이코테 최단 경로 미래 도시 - 문제 다른 풀이, BFS (0) | 2022.04.08 |
| 백준 12865 평범한 배낭 - 파이썬 : 트리가 안되는 이유 (0) | 2021.07.26 |
| 백준 12865 평범한 배낭 - 파이썬 (1) | 2021.07.25 |


